验证码识别&暴力破解
验证码识别&暴力破解
前言
对于平常Web渗透中,验证码的问题难倒一群英雄汉,前端加密+验证码更是直接放弃,所以下面就分享一下自己在渗透中对验证码识别和存在前端加密情况的暴力破解。
所有工具都是开源的,并且都是学习需求,切勿用于不法用途,觉得可以的话去给作者点个star吧。
验证码识别
burp插件-captcha-killer
captcha-killer是只专注做好对各种验证码识别技术接口的调用工具,具体点就是burp通过同一个插件,就可以适配各种验证码识别接口,无需重复编写调用代码。
原GitHub项目地址:https://github.com/c0ny1/captcha-killer
修改版GitHub项目地址:https://github.com/f0ng/captcha-killer-modified
使用说明:https://gv7.me/articles/2019/burp-captcha-killer-usage/
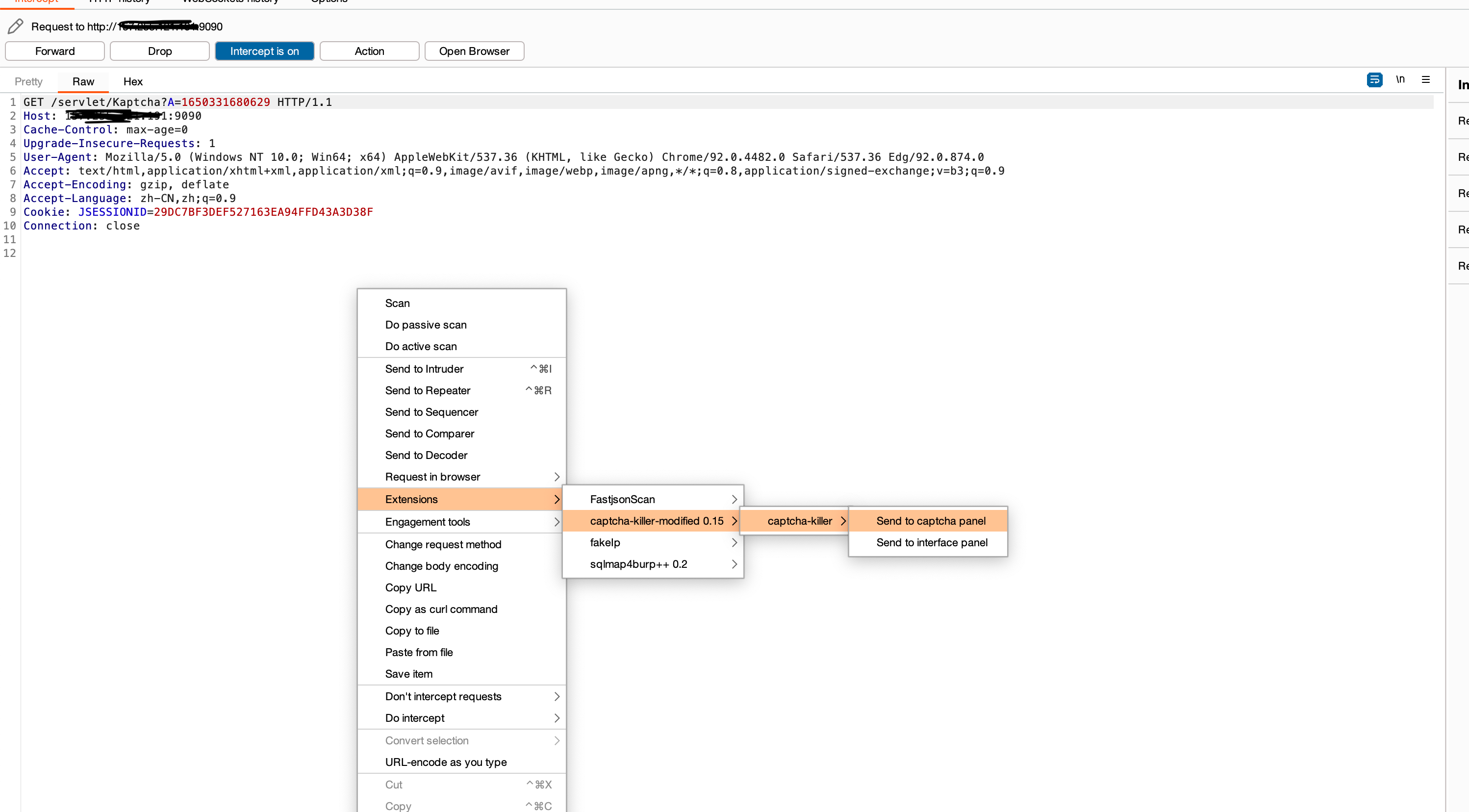
- 将获取验证码的数据包发送到插件
使用burp抓取获取验证码数据包,然后右键captcha-killer -> send to captcha panel发送数据包到插件的验证码请求面板。
然后到切换到插件面板,点击获取即可拿到要识别的验证码图片内容。
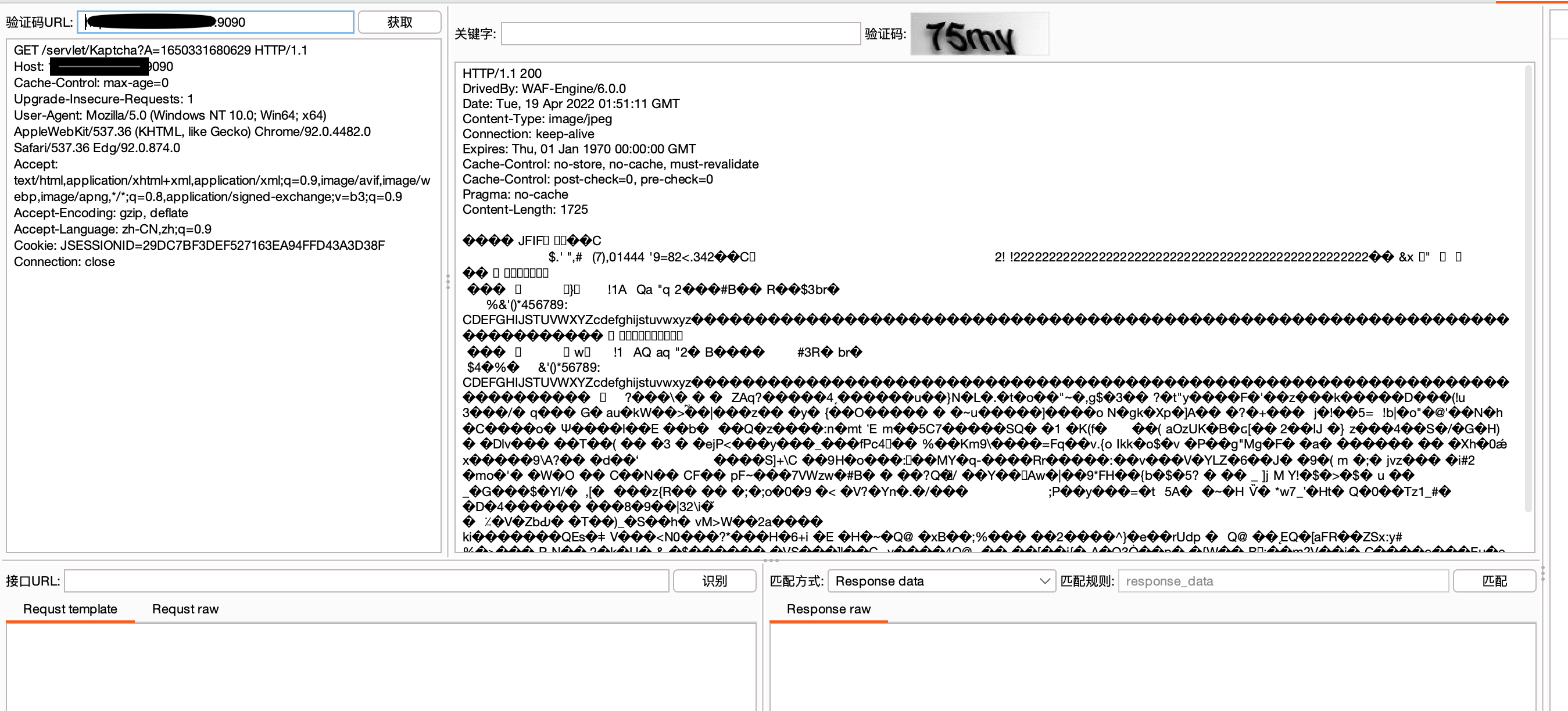
注意:获取验证码的cookie一定要和intruder发送的cookie相同!
- 配置识别接口的地址和请求包
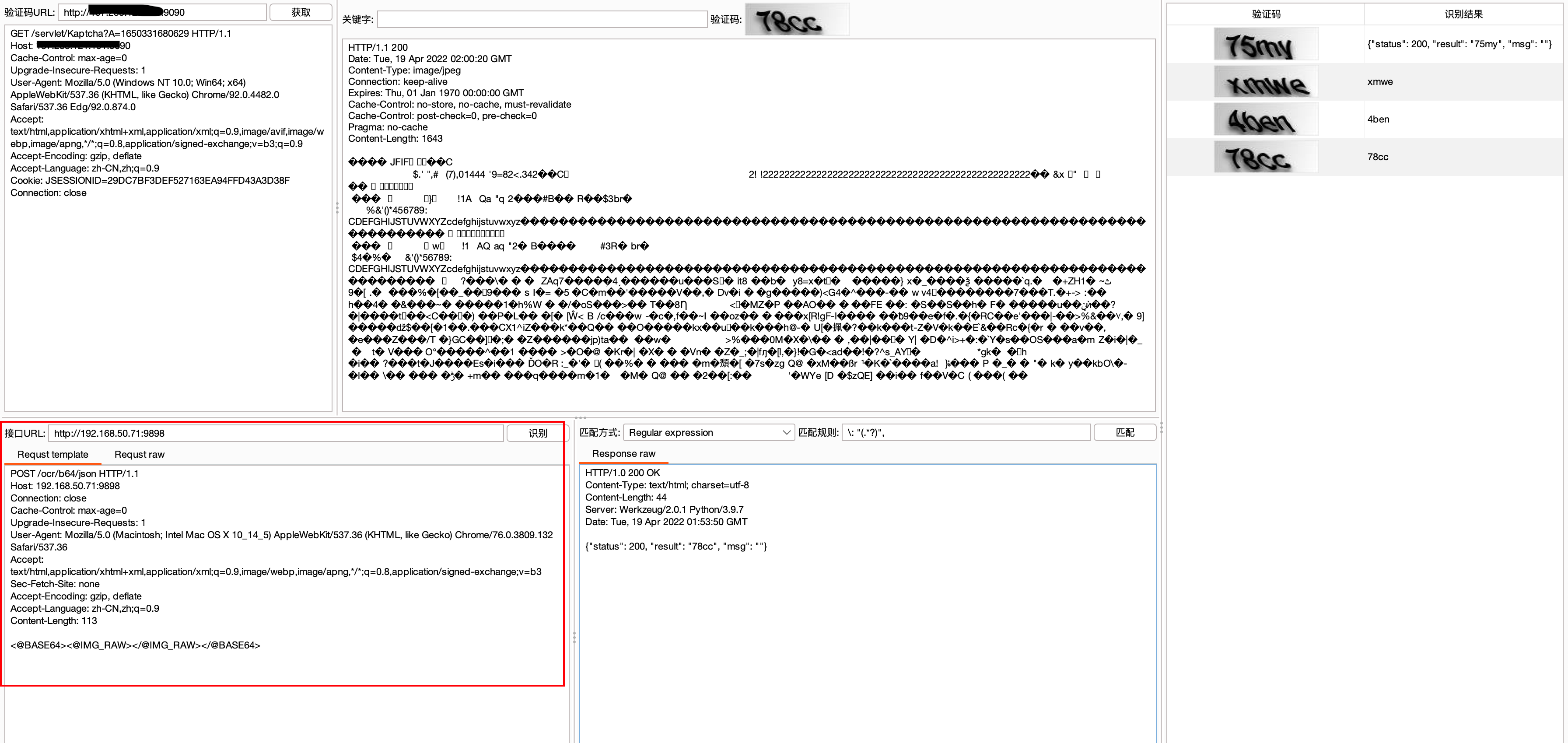
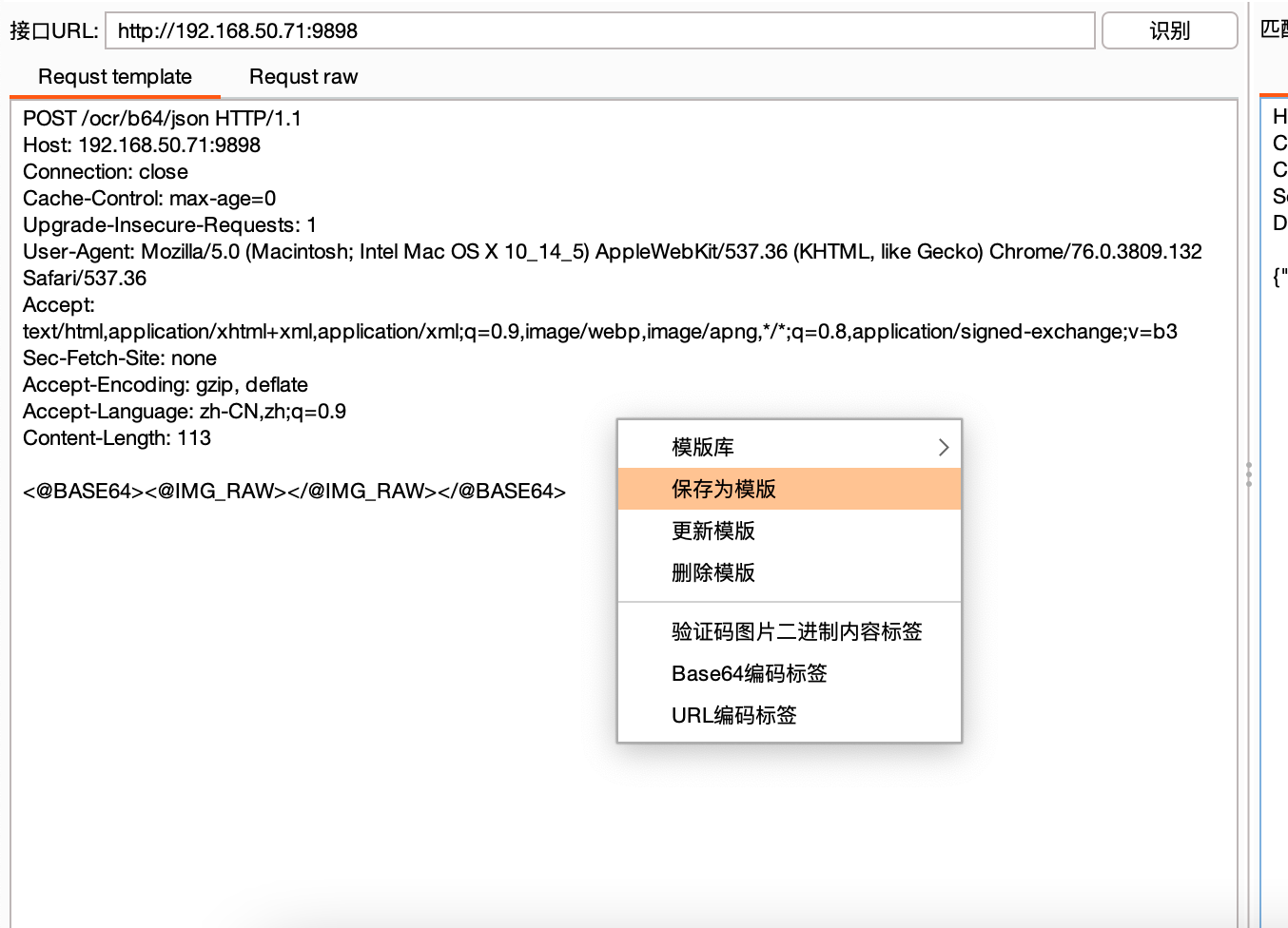
拿到验证码之后,就要设置接口来进行识别了。我们可以使用网上寻找免费的接口,也可以本地起一个验证码识别的服务
ddddocr识别接口数据包实例如下:
1 | POST /ocr/b64/json |
然后我们把图片内容的位置用标签来代替。比如该例子使用的接口是post提交image参数,参数的值为图片二进制数据的base64编码后的url编码。那么Request template(请求模版)面板应该填写如下:
| ID | 标签 | 描述 |
|---|---|---|
| 1 | <@IMG_RAW></@IMG_RAW> |
代表验证码图片原二进制内容 |
| 2 | <@URLENCODE></@URLENCODE> |
对标签内的内容进行url编码 |
| 3 | <@BASE64></@BASE64> |
对标签内的内容进行base64编码 |
后点击“识别”即可获取到接口返回的数据包,同时在request raw可以看到调用接口最终发送的请求包。
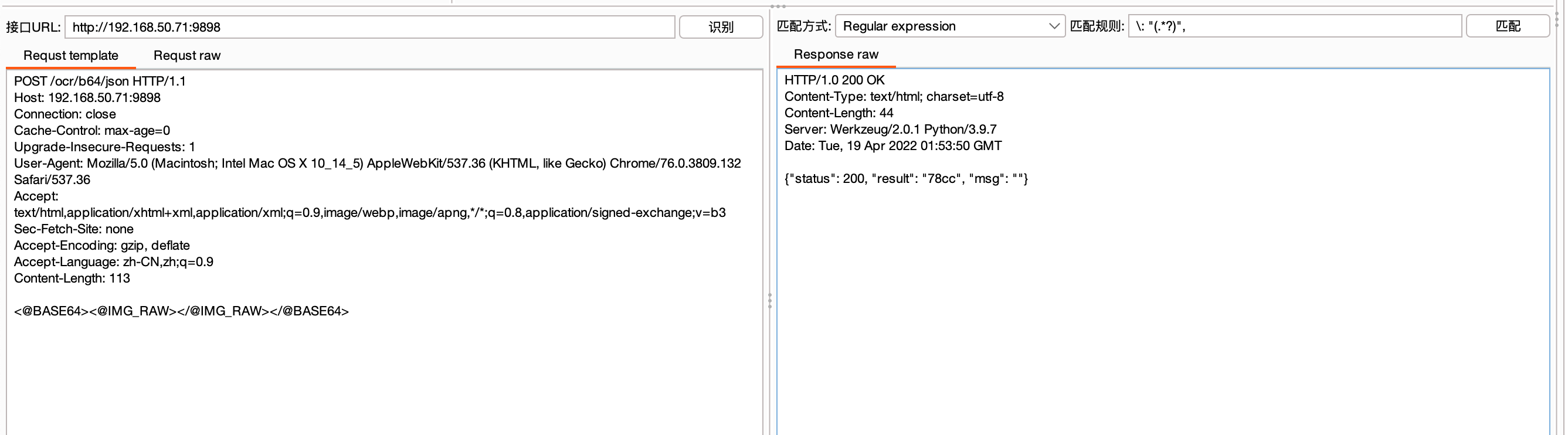
- 设置用于匹配识别结果的规则
通过上一步我们获取到了识别接口的返回结果,但是插件并不知道返回结果中,哪里是真正的识别结果。插件提供了4中方式进行匹配,可以根据具体情况选择合适的。
| ID | 规则类型 | 描述 |
|---|---|---|
| 1 | Repose data | 这种规则用于匹配接口返回包内容直接是识别结果 |
| 2 | Regular expression | 正则表达式,适合比较复杂的匹配。比如接口返回包{"coede":1,"result":"abcd"}说明abcd是识别结果,我们可以编写规则为result":"(.*?)"\} |
| 3 | Define the start and end positions | 定义开始和结束位置,使用上面的例子,可以编写规则{"start":21,"end":25} |
| 4 | Defines the start and end strings | 定义开始和结束字符,使用上面的例子,可以编写规则为{"start":"result\":\","end":"\"\}"} |
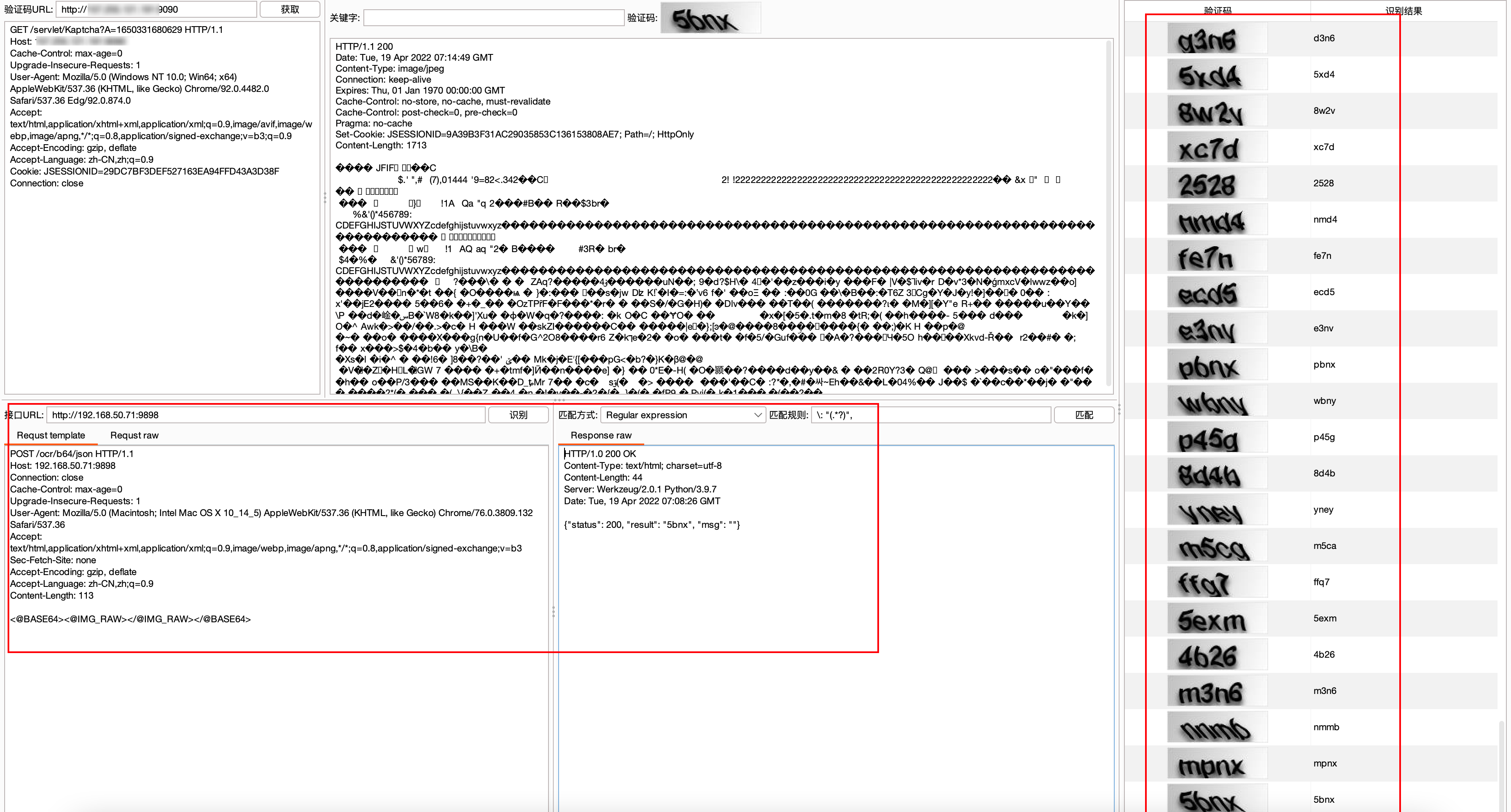
通过分析我们知道,接口返回的json数据中,字段result的值为识别结果。我们这里使用Regular expression(正则表达式)来匹配,然后选择78cc右键标记为识别结果,系统会自动生成正则表达式规则" (.*?)"\}\]。
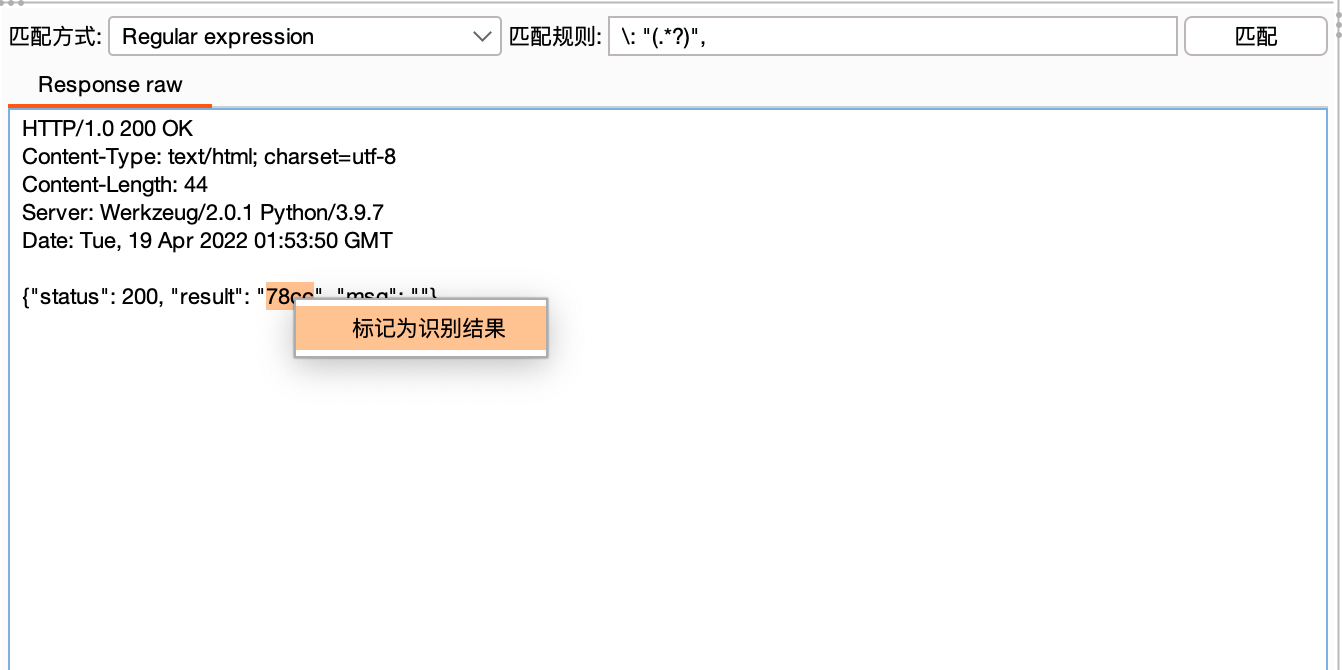
注意:若右键标记自动生成的规则匹配不精确,可以人工进行微调。比如该例子中可以微调规则为"result"\: "(.*?)"\}将更加准确!
点击识别可从右边侧栏查看准确率
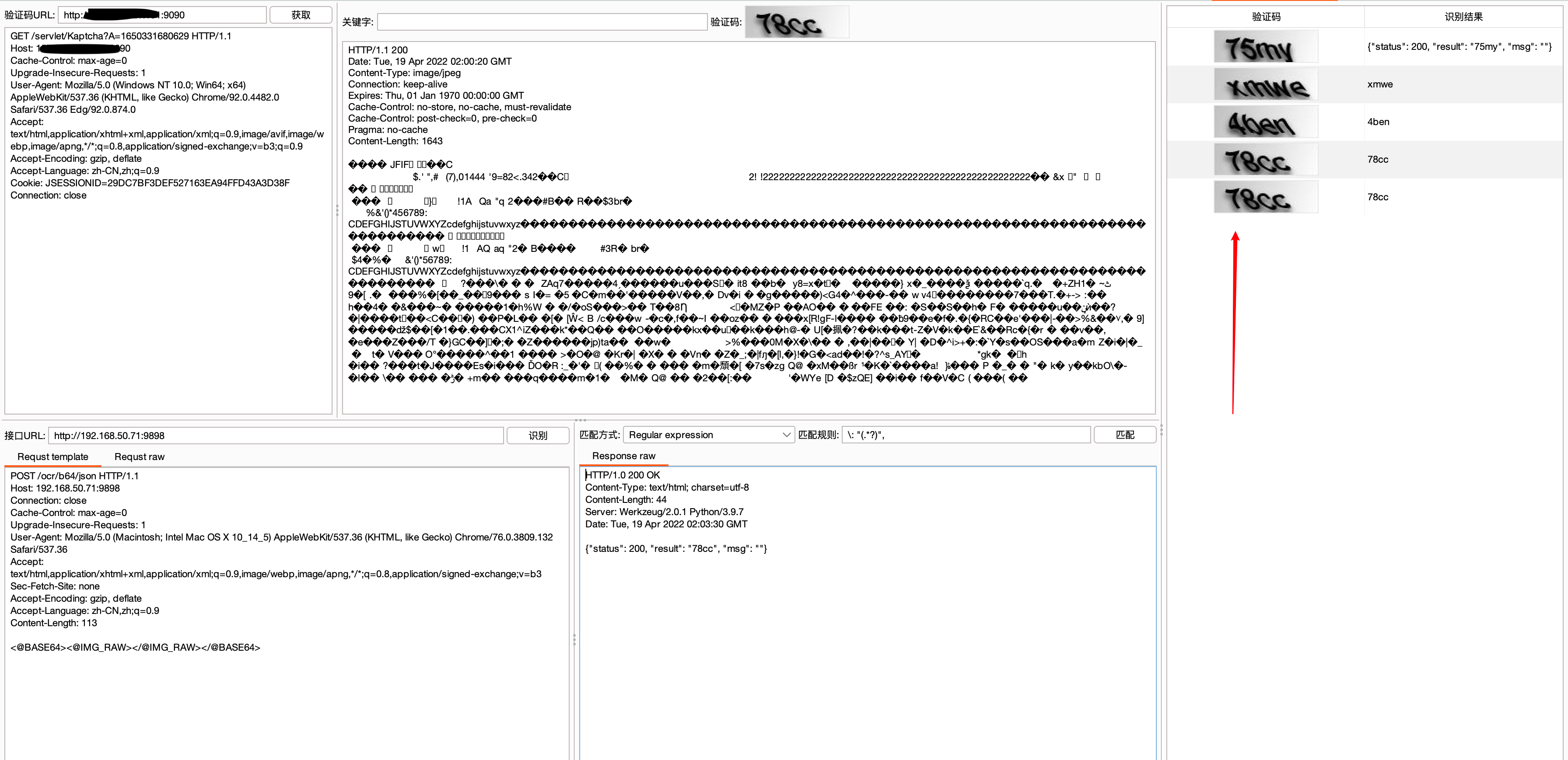
到达这步建议将配置好常用接口的url,数据包已经匹配规则保存为模版,方便下次直接通过右键模板库中快速设置。
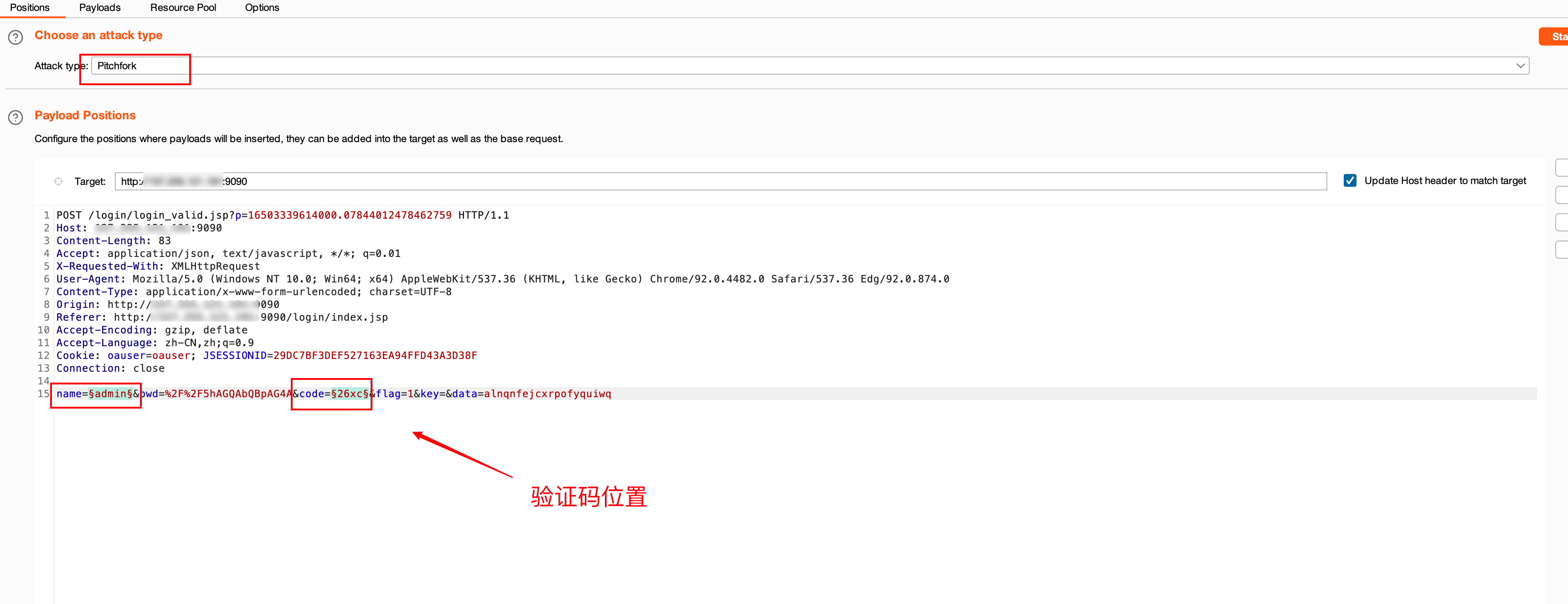
- 在Intruder模块调用
配置好各项后,可以点击锁定对当前配置进行锁定,防止被修改导致爆破失败!接着按着以下步骤进行配置
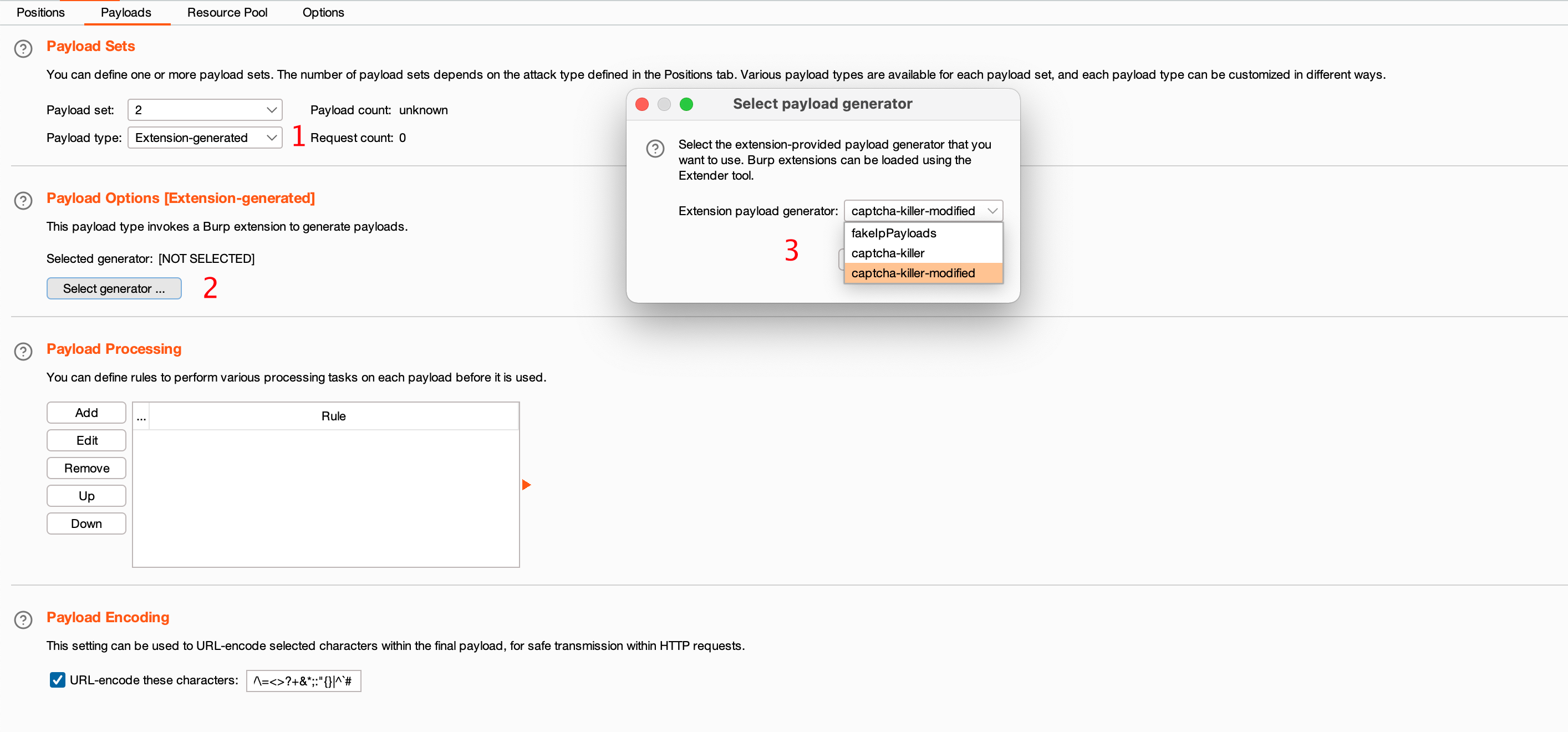
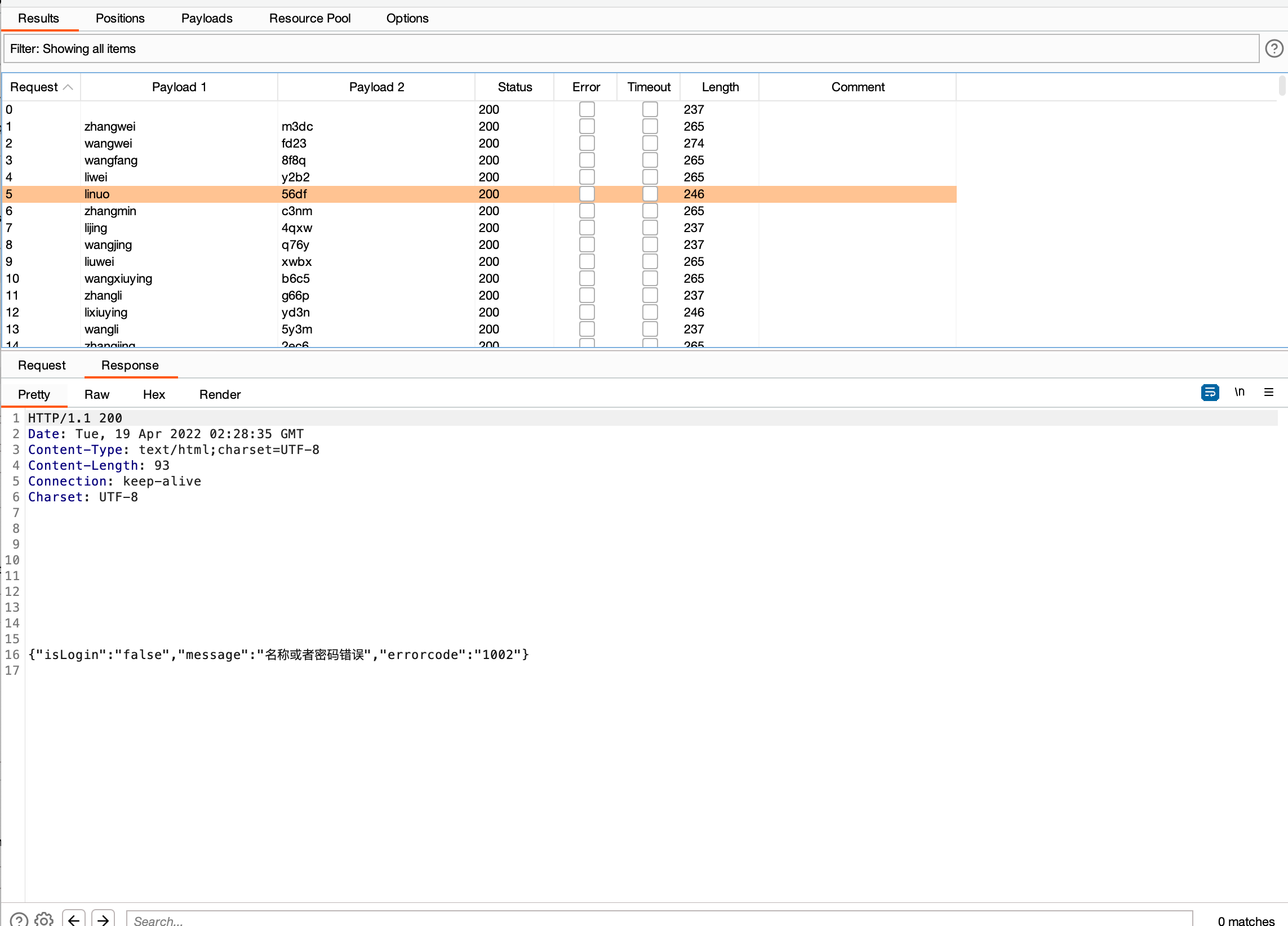
即可进行爆破
ddddocr
https://github.com/sml2h3/ddddocr
简介
ddddocr是由sml2h3开发的专为验证码厂商进行对自家新版本验证码难易强度进行验证的一个python库,其由作者与kerlomz共同合作完成,通过大批量生成随机数据后进行深度网络训练,本身并非针对任何一家验证码厂商而制作,本库使用效果完全靠玄学,可能可以识别,可能不能识别。
使用ocr_api_server一键启动识别服务
https://github.com/sml2h3/ocr_api_server
- 最简单运行方式
1 | # 安装依赖 |
- docker运行方式(目测只能在Linux下部署)
1 | git clone https://github.com/sml2h3/ocr_api_server.git |
- 接口
1 | # 1、测试是否启动成功,可以通过直接GET访问http://{host}:{port}/ping来测试,如果返回pong则启动成功 |
详细实操步骤:
- step1:安装下载项目依赖
1 | git clone https://github.com/sml2h3/ocr_api_server.git |
1 | python3 -m pip install -r requirements.txt -i https://pypi.douban.com/simple |
- step2:运行开启
1 | # 最简单运行方式,只开启ocr模块并以新模型计算 |
可根据需求运行相应的命令
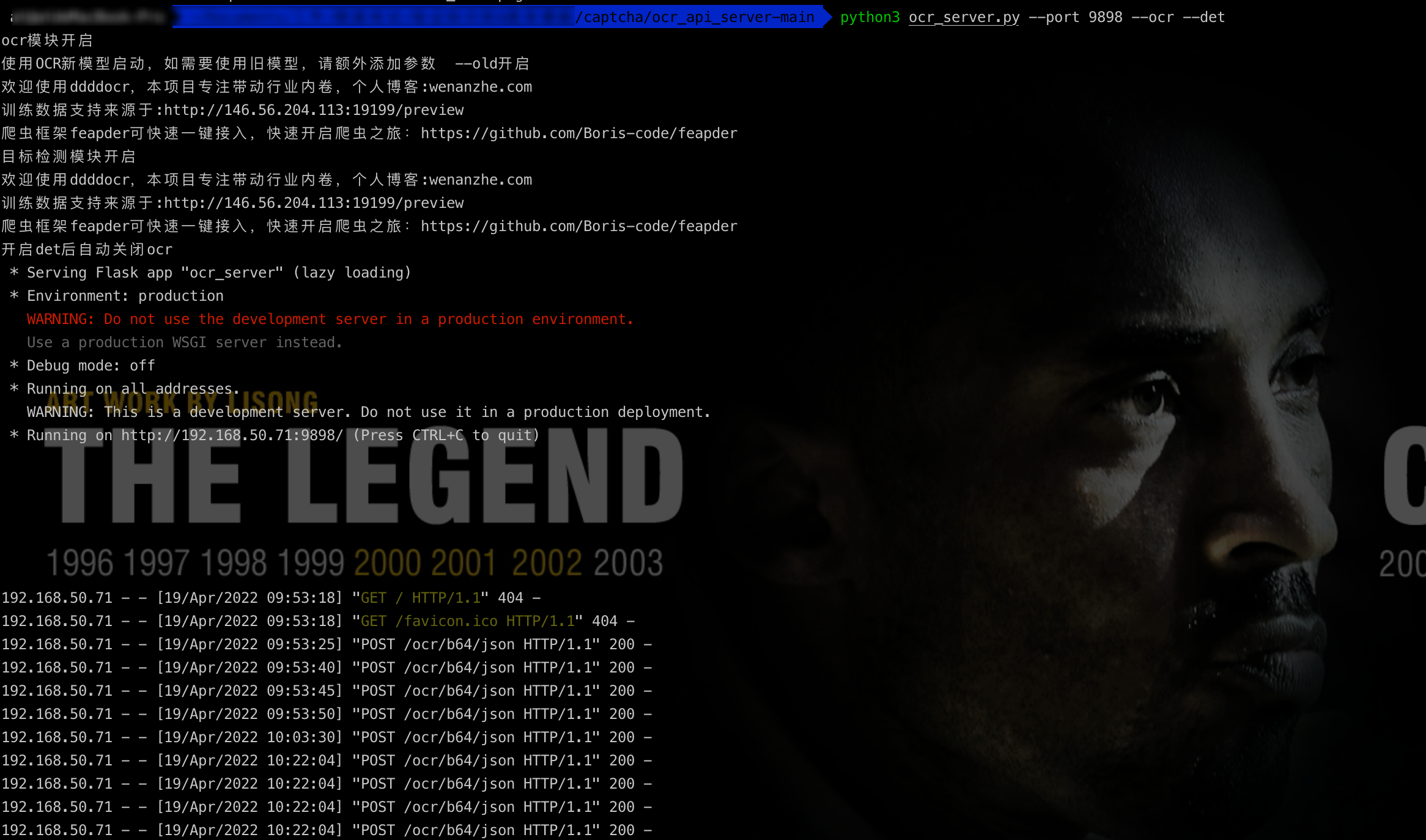
- step3:接口格式类型
常用请求模版:
1 | POST /ocr/b64/json |
配合burp的captcha-killer插件使用,识别准确率还是杠杠的
同时作者还公开其训练的脚本,感兴趣的可以自己搞张显卡训练,训练项目如下:
https://github.com/sml2h3/dddd_trainer
dist-cpu
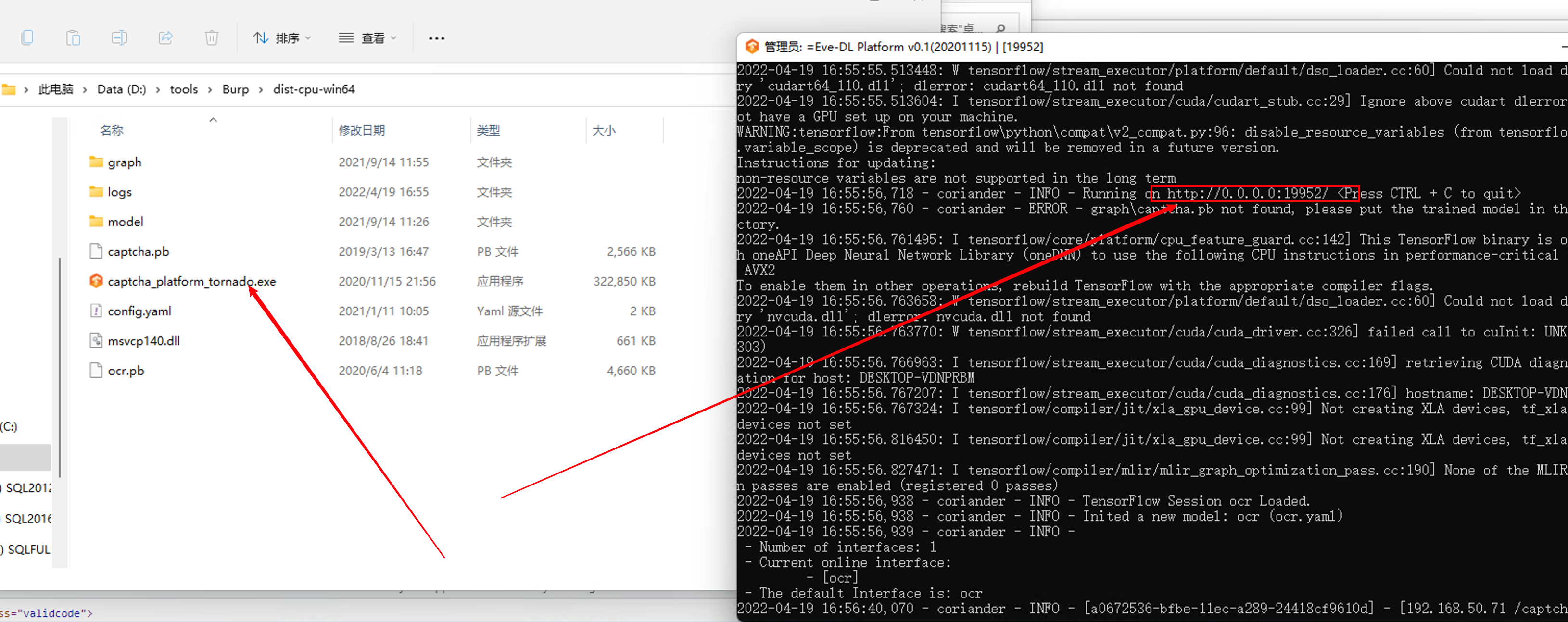
dist-cpu是已经训练好的ocr识别项目(现github地址已删除)
双击exe即可运行,监听地址为http://0.0.0.0:19952/,监听地址和端口可在config.yaml中更改
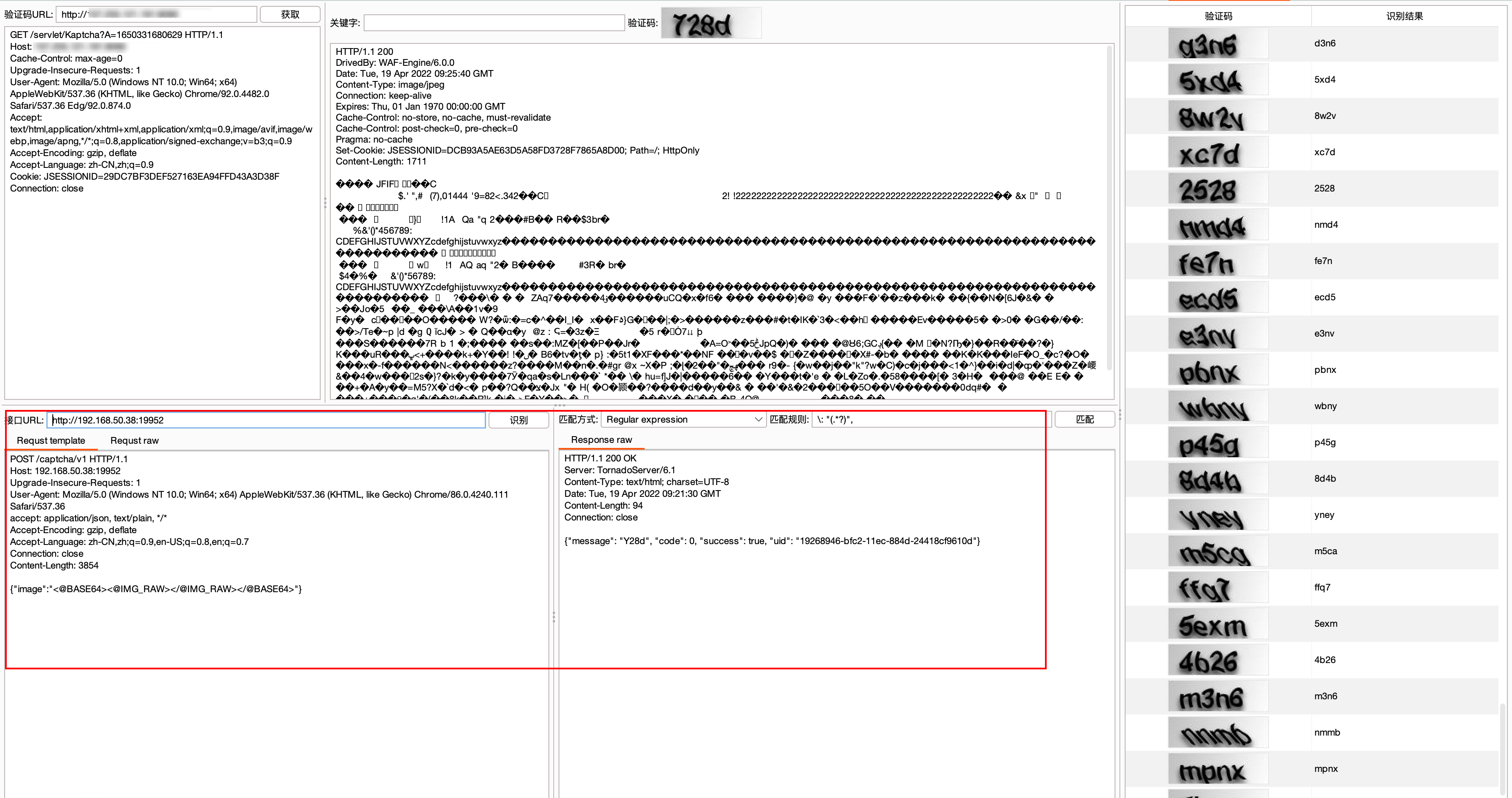
1 | POST /captcha/v1 |
配合burp插件captcha-kiler使用,使用方法和ddddocr类似,效果比ddddocr差些
PKAV HTTP Fuzzer
需要安装.net framework 4.0或以上版本。
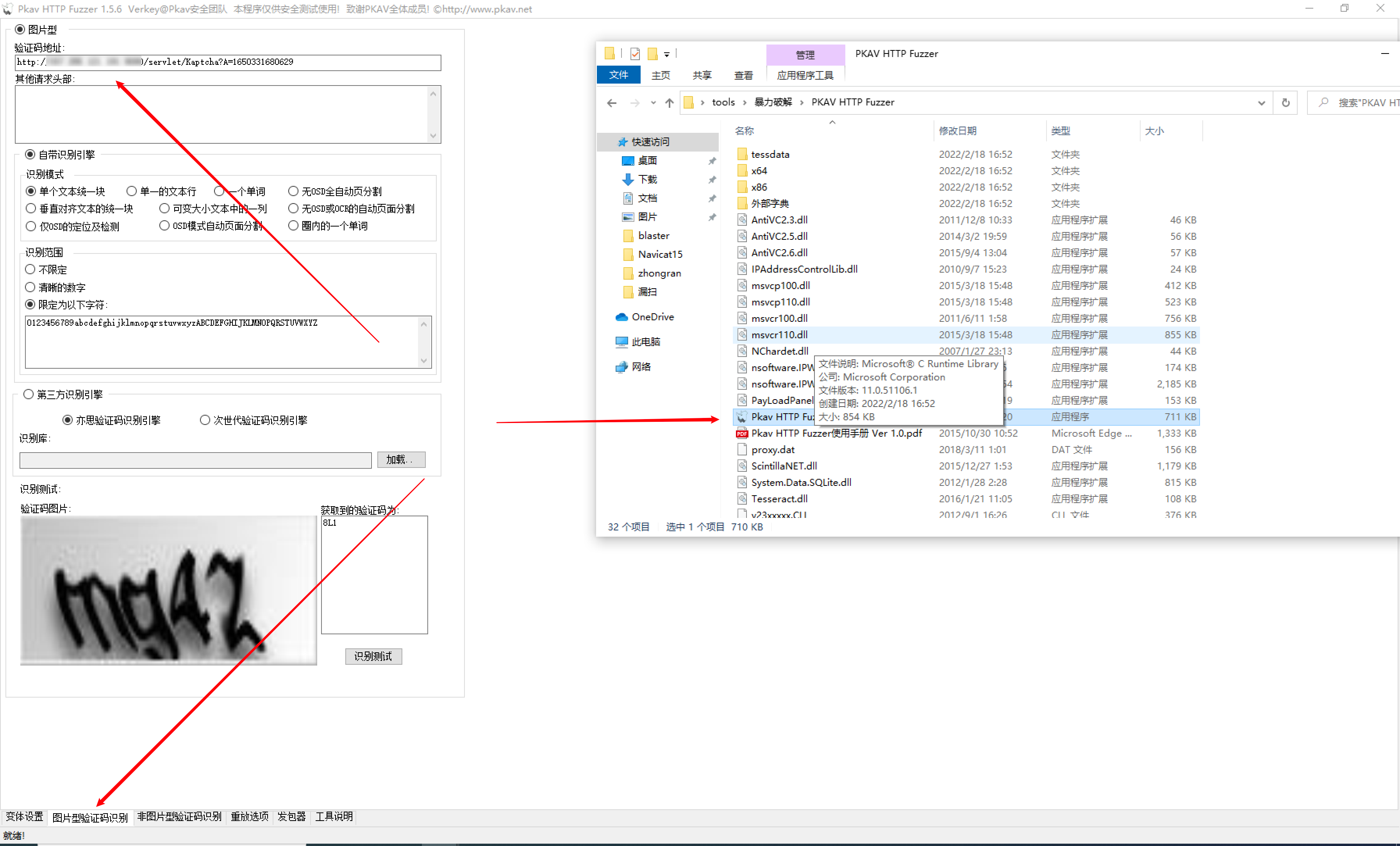
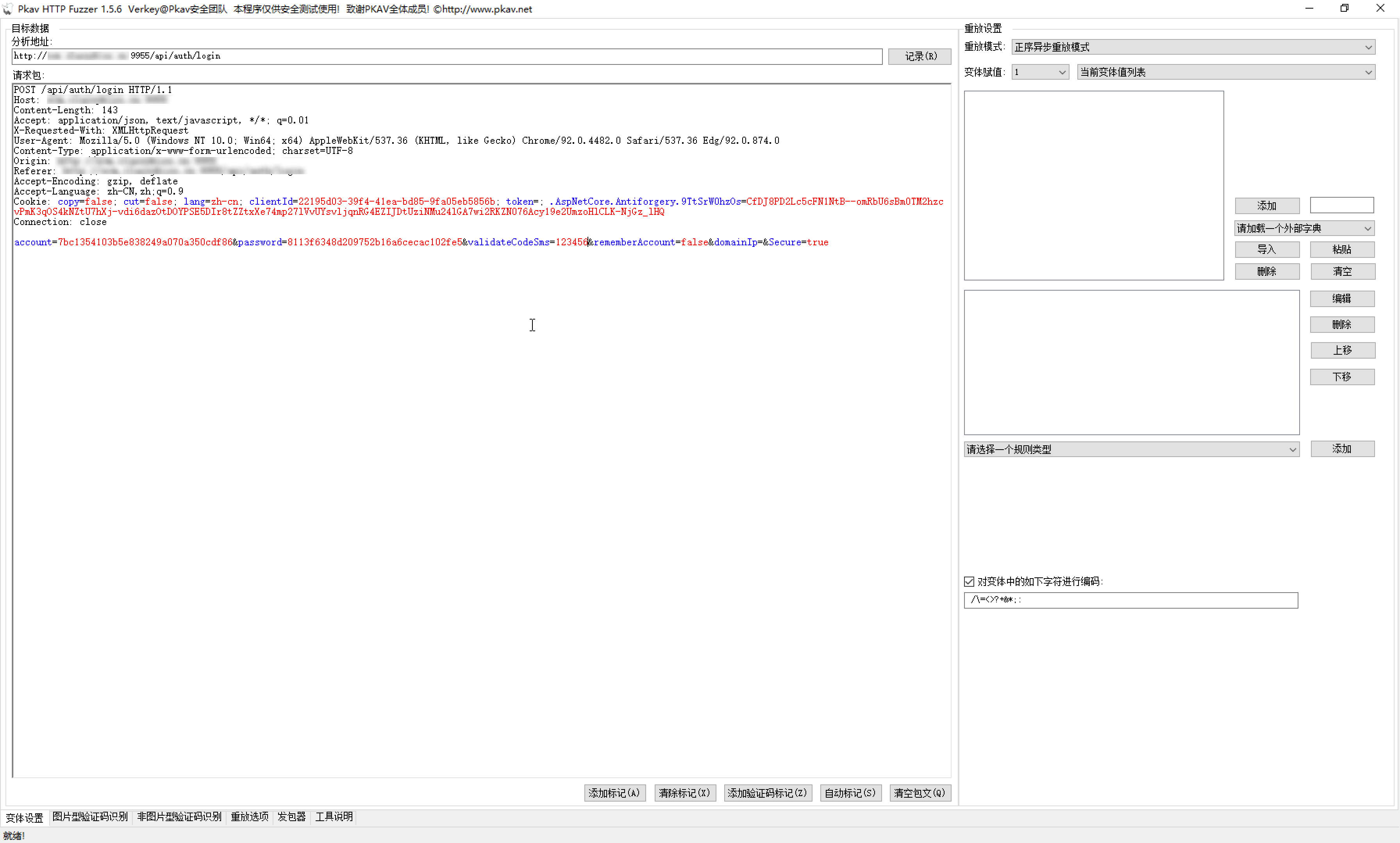
暴力破解
blaster+ddddocr
https://github.com/PoJun-Lab/blaster
blaster 是一款弱密码隐患检测工具,用于网站登录弱密码检测。
无论是在漏洞响应平台,还是日常工作中,大家或许在为图片验证码、登录加密等无法直接登录测试而烦恼,所以blaster应运而生。它支持导入用户名密码字典,多并发图片验证码识别,自动填充表单元素,无视任何登录加密。
- 支持复选框勾选:主要场景为阅读平台使用须知、 隐私政策单选表单等。
- 支持复杂场景的事件操作:可根据不同场景,在登录前后自定义事件操作。
- 支持正则匹配反向过滤:应对不同响应类型、长度,提取关键信息进行反向过滤。
- 图片验证码识别:采用python第三方库进行ocr识别。
- 无视任何加密方式:它将用户名及密码字典填充至对应表单进行提交,无需逆向加密方式。
- 支持多次输入账号密码错误才出现验证码情况
- 支持多并发
配置
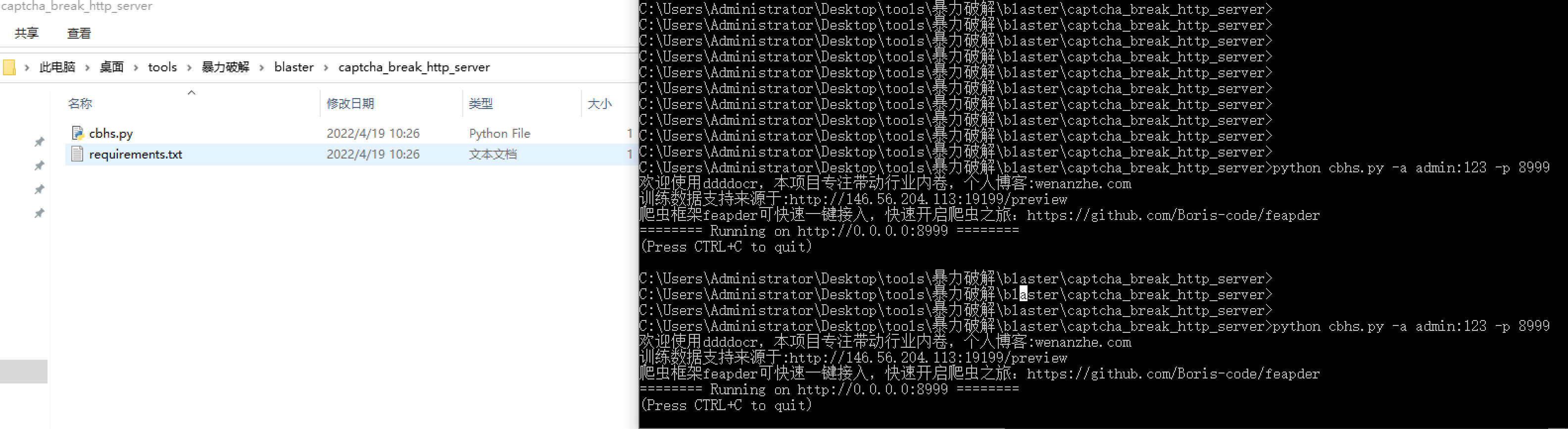
服务端搭建,该服务对应客户端配置中的 captchabreak_serverurl,它用于图片验证码识别。
1 | python3 cbhs.py -a user:pass -p port # 自定义服务端basic认证用户名密码、开放端口 |
客户端配置 config.yaml
1 | # 示例目标网址:http://www.example.com/login |
captchabreak_serverurl
- 用于指定图片验证码服务,格式为 http://user:pass@127.0.0.1:port/cb
before_all_js_expr
在开始填写账号密码之前执行的js表达式,如页面打开后有弹出层,可以将通过该参数关闭弹窗,不局限于弹出层一个场景。
示例场景:打开页面出现弹出层,需要关闭弹窗后输入账号密码。
示例解决弹出层:判断某按钮(弹出层关闭按钮X)是否存在,如果存在则点击;找出关闭按钮的js path按照格式编写代码即可。
1
null != jspath && jspath.click() // js代码格式
表达式不限于一个,如有其他场景或多个弹出层,可通过 && 或 || 进行叠加
before_login_js_expr
在点击登录之前执行的js表达式,如登录需要勾选阅读平台使用须知、 隐私政策单选表单等
示例场景:输入账号密码后需要选择阅读平台使用须知、 隐私政策等表单才可登录
示例解决表单勾选:判断某勾选框是否已经勾选如果未勾选则点击;找出表单勾选的js path按照格式编写代码即可。
1
!jspath.checked && jspath.click() // js代码格式
表达式不限于一个,如有其他场景或多个勾选,可通过 && 或 || 进行叠加
body_exclude_regex
排除请求的正则,即只要命中其中任意一个正则的请求响应将被抛弃,即反向grep。
示例场景:登录后的响应页面长度较大,返回格式为HTML,其中有(账号不存在、密码错误、验证码错误、登录成功)等不同情况,由于响应长度较大我们无法轻易区分测试数据的真实响应情况。
示例解决响应长度较大问题:经过手工登录测试发现响应的HTML中出现这些关键信息(如账号不存在、密码错误、验证码错误),根据自己的需求,编写正则表达式,在发现响应中存在这些匹配内容时不输出到终端及结果文件中。
这里需要具备一些正则表达式的技能,如果使用者技能有些欠缺,可以直接使用关键信息进行排除,或是在交流群内寻求帮助。
1
2
3body_exclude_regex:
- '账号不存在'
- '验证码错误'该参数不限于一个表达式,使用者根据自己的需求来增删表达式即可。
客户端配置中的jspath可在浏览器页面对应表单右键选择检查(Inspect),并在检查中右键选中的表单标签,选择Copy>Copy JS path即可复制jspath。
使用
1 | C:\Users\balster>blaster_win.exe |
1 | C:\Users\blaster>blaster_win.exe -c conf.yaml -u user.txt -p pwds.txt -o res.csv |
使用操作实例
1、验证码服务启动(没验证码就不用,且注释配置文件关于验证码选项)
2、配置config.yaml
1 | # 示例目标网址:http://www.example.com/login |
注:里面的loginreq_pattern通配符*必不可少
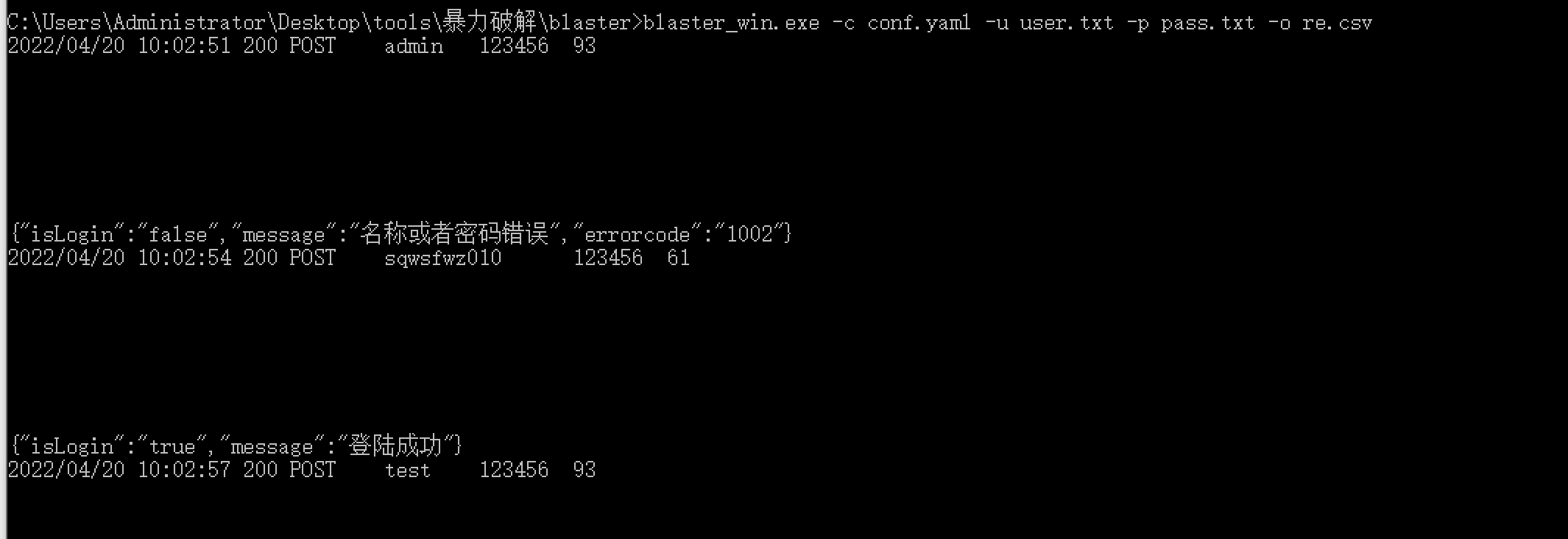
3、运行
1 | blaster_win.exe -c conf.yaml -u user.txt -p pass.txt -o re.csv |
参考链接
https://github.com/c0ny1/captcha-killer
https://github.com/f0ng/captcha-killer-modified
https://gv7.me/articles/2019/burp-captcha-killer-usage/
https://github.com/sml2h3/ddddocr